Sinhala script
| Sinhala | |
|---|---|
| Type | Abugida |
| Spoken languages | Sinhala |
| Time period | c. 700–present |
| Parent systems |
Proto-Sinaitic alphabet
|
| Child systems | Dhives Akuru |
| Sister systems | Telugu script Kannada script Malayalam script Tamil script Tulu script |
| Unicode range | U+0D80–U+0DFF |
| ISO 15924 | Sinh |
| Note: This page may contain IPA phonetic symbols. | |

|
|||||||||||
The Sinhala script is an abugida script used in Sri Lanka to write the official language Sinhala and also sometimes the liturgical languages Pali and Sanskrit.[1] Being a member of the Brahmic family of scripts, the Sinhala script can trace its ancestry back more than 2000 years.[1]
Sinhala is often considered two alphabets, or an alphabet with another alphabet, due to the presence of two different sets of letters. The core set, known as the śuddha siṃhala (Pure Sinhala, ශුද්ධ සිංහලimg) or eḷu hōḍiya (Eḷu alphabet එළු හෝඩියimg), can represent all native phonemes. In order to render Sanskrit and Pali words, an extended set, the miśra siṃhala (Mixed Sinhala, මිශ්ර සිංහලimg), is available.[2]
Characteristics

The alphabet is written from left to right. The Sinhala writing system can be called an abugida, as each consonant has an inherent vowel (/a/), which can be changed with the different vowel signs (see image on left).
Most of the Sinhala letters are curlicues; straight lines are almost completely absent from the alphabet. This is because Sinhala used to be written on dried palm leaves, which would split along the veins on writing straight lines. This was undesirable, and therefore, the round shapes were preferred.
The core set of letters forms the śuddha siṃhala alphabet (Pure Sinhala, ශුද්ධ සිංහලimg), which is a subset of the miśra siṃhala alphabet (Mixed Sinhala, මිශ්ර සිංහලimg). This 'pure' alphabet contains all the graphemes necessary to write Eḷu (classical Sinhala) as described in the classical grammar Sidatsan̆garā (1300 AD).[3] This is the reason why this set is also called Eḷu hōdiya ('Eḷu alphabet' එළු හෝඩියimg).
The definition of the two sets is thus a historic one. Out of pure coincidence, the phoneme inventory of present day colloquial Sinhala is such that yet again the śuddha alphabet suffices as a good representation of the sounds.[3]
All native phonemes of the Sinhala spoken today can be represented in śuddha, while in order to render special Sanskrit and Pali sounds, one can fall back on miśra siṃhala. This is most notably necessary for the graphemes for the Middle Indic phonemes that the Sinhalese language lost during its history, such as aspirates.[3]
Sinhalese had special symbols to represent numerals, which were in use until the beginning of the [19th] century. This system is now superseded by Arabic numerals.[4][5]
Neither the Sinhala numerals nor U+0DF4 ෴ Sinhala punctuation kunddaliya is in general use today. The kunddaliya was formerly used as a full stop; it is included for scholarly use. The Sinhala numerals are not presently encoded.[6]
History and usage
The Sinhala script originated as an offshoot from Brahmi.[1] and is founded in the southern branch of this family, sharing a lineage with scripts such as Malayalam, and Tamil.[7] The writing system was originally used in inscriptions, the oldest ones dating from the 6th century BCE on pottery[8], with lithic inscriptions dating from the second century B.C.[9] By the ninth century C.E.., literature written in Sinhala script had emerged and the script began to be used in other contexts. For instance, the Buddhist literature of the Theravada-Buddhists of Sri Lanka, written in Pali, used the Sinhala alphabet.
Today, the alphabet is used by approx. 16,000,000 people to write the Sinhalese language in very diverse contexts, such as newspapers, TV commercials, government announcements, graffiti, and schoolbooks.
Sinhala is the main language written in this alphabet, but rare instances of Sri Lanka Malay written in this script are recorded.
Relations between orthography and phonology
Most phonemes of the Sinhalese language can be represented by a śuddha letter or by a miśra letter, but normally only one of them is considered correct. This one-to-many mapping of phonemes onto graphemes is a frequent source of misspellings.[10]
While a phoneme can be represented by more than one grapheme, each grapheme can be pronounced in only one way. This means that the actual pronunciation of a word is always clear from its orthographic form.
Śuddha graphemes
The śuddha graphemes are the mainstay of the Sinhala alphabet and are used on an everyday-basis. Every sequence of sounds of the Sinhalese language of today can be represented by these graphemes. Additionally, the śuddha set comprises graphemes for retroflex <ḷ> and <ṇ>, which are no longer phonemic in modern Sinhala. These two letters were needed for the representation of Eḷu, but are now obsolete from a purely phonemic view. However, words which historically contain these two phonemes are still often written with the graphemes representing the retroflex sounds.
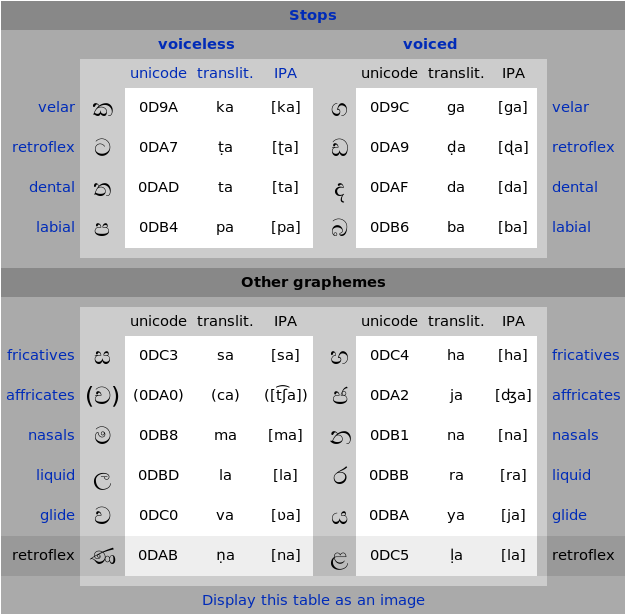
Consonants
The śuddha alphabet comprises 8 stops, 2 fricatives, 2 affricates, 2 nasals, 2 liquids and 2 glides. Additionally, there are the two graphemes for the retroflex sounds /ɭ/ and /ɳ/, which are not phonemic in modern Sinhala, but which still form part of the set. These are shaded in the table.
The voiceless affricate (ච [t͡ʃa]) is not included in the śuddha set by purists since it does not occur in the main text of the Sidatsan̆garā. The Sidatsan̆garā does use it in examples though, so this sound did exist in Eḷu. In any case, it is needed for the representation of modern Sinhala.[3]
The basic shapes of these consonants carry an inherent /a/ unless this is replaced by another vowel or removed by the hal kirīma.
|
(Click on [show] on the right if you only see boxes below)
|
|||||||||||
| Stops | |||||||||||
| voiceless | voiced | ||||||||||
| unicode | translit. | IPA | unicode | translit. | IPA | ||||||
| velar | ක | 0D9A | ka | [ka] | ග | 0D9C | ga | [ɡa] | velar | ||
| retroflex | ට | 0DA7 | ṭa | [ʈa] | ඩ | 0DA9 | ḍa | [ɖa] | retroflex | ||
| dental | ත | 0DAD | ta | [ta] | ද | 0DAF | da | [da] | dental | ||
| labial | ප | 0DB4 | pa | [pa] | බ | 0DB6 | ba | [ba] | labial | ||
| Other graphemes | |||||||||||
| unicode | translit. | IPA | unicode | translit. | IPA | ||||||
| fricatives | ස | 0DC3 | sa | [sa] | හ | 0DC4 | ha | [ha] | fricatives | ||
| affricates | (ච) | (0DA0) | (ca) | ([t͡ʃa]) | ජ | 0DA2 | ja | [d͡ʒa] | affricates | ||
| nasals | ම | 0DB8 | ma | [ma] | න | 0DB1 | na | [na] | nasals | ||
| liquid | ල | 0DBD | la | [la] | ර | 0DBB | ra | [ra] | liquid | ||
| glide | ව | 0DC0 | va | [ʋa] | ය | 0DBA | ya | [ja] | glide | ||
| retroflex | ණ | 0DAB | ṇa | [na] | ළ | 0DC5 | ḷa | [la] | retroflex | ||
| Display this table as an image | |||||||||||
Vowels
.svg.png)
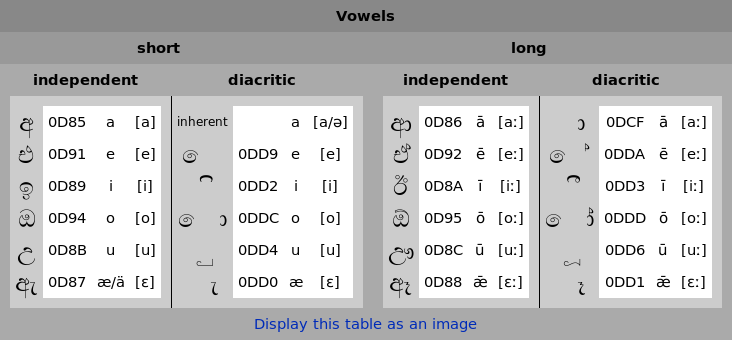
Vowels come in two shapes: independent and diacritic. The independent shape is used when a vowel does not follow a consonant, e.g. at the beginning of a word. The diacritic shape is used when a vowel follows a consonant. Depending on the vowel, the diacritic can attach at several places. The diacritic for <i> attaches above the consonant, the diacritic for <u> attaches below, the diacritic for <ā> follows, while the diacritic for <e> precedes. <o> finally is marked by the combination of preceding <e> and following <ā>.
While <a,e,i,o> are regular, the diacritic for <u> takes a different shape according to the consonant it attaches to. The most common one is represented on the image on the right for the consonant ප (p). The k-shape is used for some consonants ending at the lower right corner (ක (k),ග (g), ත(t), but not න(n) or හ(h)). Combinations of ර(r) or ළ(ḷ) with <u> have idiosyncratic shapes.[11]
|
(Click on [show] on the right if you only see boxes below)
|
|||||||||||||||||||||||
| Vowels | |||||||||||||||||||||||
| short | long | ||||||||||||||||||||||
| independent | diacritic | independent | diacritic | ||||||||||||||||||||
| අ | 0D85 | a | [a] | inherent | a | [a, ə] | ආ | 0D86 | ā | [aː] | ා | 0DCF | ā | [aː] | |||||||||
| එ | 0D91 | e | [e] | ෙ | 0DD9 | e | [e] | ඒ | 0D92 | ē | [eː] | ේ | 0DDA | ē | [eː] | ||||||||
| ඉ | 0D89 | i | [i] | ි | 0DD2 | i | [i] | ඊ | 0D8A | ī | [iː] | ී | 0DD3 | ī | [iː] | ||||||||
| ඔ | 0D94 | o | [o] | ො | 0DDC | o | [o] | ඕ | 0D95 | ō | [oː] | ෝ | 0DDD | ō | [oː] | ||||||||
| උ | 0D8B | u | [u] | ු | 0DD4 | u | [u] | ඌ | 0D8C | ū | [uː] | ූ | 0DD6 | ū | [uː] | ||||||||
| ඇ | 0D87 | æ/ä | [æ] | ැ | 0DD0 | æ | [æ] | ඈ | 0D88 | ǣ | [æː] | ෑ | 0DD1 | ǣ | [æː] | ||||||||
| Display this table as an image | |||||||||||||||||||||||
Prenasalized consonants
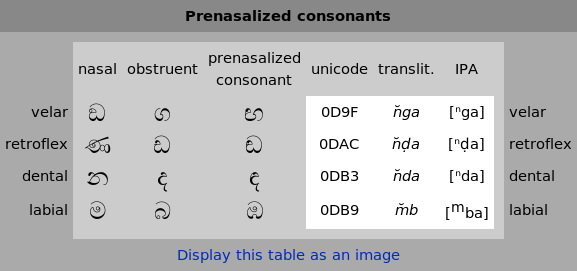
The prenasalized consonants resemble their plain counterparts. <m̆b> is made up by the left half of <m> and the right half of <b>, while the other three are just like the grapheme for the stop with a little stroke attached to their left.[12] Vowel diacritics attach in the same way as they would to the corresponding plain stop.
|
(Click on [show] on the right if you only see boxes below)
|
||||||||
| Prenasalized consonants | ||||||||
| nasal | obstruent | prenasalized consonant |
unicode | translit. | IPA | |||
| velar | ඞ | ග | ඟ | 0D9F | n̆ga | [ⁿɡa] | velar | |
| retroflex | ණ | ඩ | ඬ | 0DAC | n̆ḍa | [ⁿɖa] | retroflex | |
| dental | න | ද | ඳ | 0DB3 | n̆da | [ⁿda] | dental | |
| labial | ම | බ | ඹ | 0DB9 | m̆ba | [mba] | labial | |
| Display this table as an image | ||||||||
Non-vocalic diacritics

The Anusvara (often called binduva 'zero' ) is represented by one small circle ං (unicode 0D82),[13] and the Visarga (technically part of the miśra alphabet) by two ඃ (unicode 0D83). The inherent vowel can be removed by a special diacritic, the hal kirīma(්), which varies in shape according to the consonant it attaches to. Both are represented in the image on the right side. The first one is the most common one, while the second one is used for letters ending at the top left corner.
Miśra set
The miśra alphabet is a superset of śuddha. It adds letters for aspirates, retroflexes and sibilants, which are not phonemic in today's Sinhala, but which are necessary to represent non-native words, like loanwords from Sanskrit, Pali or English. The use of the extra letters is mainly a question of prestige. From a purely phonemic point of view, there is no benefit in using them, and they can be replaced by a (sequence of) śuddha letters as follows: For the miśra aspirates, the replacement is the plain śuddha counterpart, for the miśra retroflex liquids the corresponding śuddha coronal liquid,[14] for the sibilants, <s>.[15] ඤ (ñ) and ඥ (gn) cannot be represented by śuddha graphemes, but are only found in less than 10 words each. ෆ fa can be represented by ප pa with a Latin <f> inscribed in the cup.
|
(Click on [show] on the right if you only see boxes below)
|
|||||||||||
| Extra miśra stops | |||||||||||
| voiceless | voiced | ||||||||||
| unicode | translit. | IPA | unicode | translit. | IPA | ||||||
| velar | ඛ | 0D9B | kha | [ka] | ඝ | 0D9D | gha | [ɡa] | velar | ||
| retroflex | ඨ | 0DA8 | ṭha | [ʈa] | ඪ | 0DAA | ḍha | [ɖa] | retroflex | ||
| dental | ථ | 0DAE | tha | [ta] | ධ | 0DB0 | dha | [da] | dental | ||
| labial | ඵ | 0DB5 | pha | [pa] | භ | 0DB7 | bha | [ba] | labial | ||
| Other additional miśra graphemes | |||||||||||
| unicode | translit. | IPA | unicode | translit. | IPA | ||||||
| sibilants | ශ | 0DC1 | śa | [sa] | ෂ | 0DC2 | ṣa | [sa] | sibilants | ||
| aspirate affricates | ඡ | 0DA1 | cha | [t͡ʃa] | ඣ | 0DA3 | jha | [d͡ʒa] | aspirate affricates | ||
| nasals | ඤ | 0DA4 | ña | [ɲa] | ඥ | 0DA5 | gna | [ɡna] | nasals | ||
| other | ඞ | 0D9E | ṅa | [ŋa] | ෆ | 0DC6 | fa | [fa, ɸa, pa] | other | ||
| other | ඦ | 0DA6 | n̆ja[16] | [nd͡ʒa] | fප | n/a | fa | [fa, ɸa, pa] | other | ||
| Display this table as an image | |||||||||||
There are six additional vocalic diacritics in the miśra alphabet. The two diphthongs are quite common, while the syllabic ṛ is much rarer, and the syllabic ḷ is all but obsolete. They are almost exclusively found in loanwords from Sanskrit.[17]
The miśra <ṛ> can be also be written with śuddha <r>+<u> or <u>+<r>, which corresponds to the actual pronunciation. The miśra syllabic <ḷ> is obsolete, but can be rendered by śuddha <l>+<i>.[18] Miśra <au> is rendered as śuddha <awu>, miśra <ai> as śuddha <ayi>.
|
(Click on [show] on the right if you only see boxes below)
|
|||||||||||||||||||||||
| Vocalic diacritics | |||||||||||||||||||||||
| independent | diacritic | independent | diacritic | ||||||||||||||||||||
| diphthongs | ඓ | 0D93 | ai | [ai] | ෛ | 0DDB | ai | [ai] | ඖ | 0D96 | au | [au] | ෞ | 0DDE | au | [au] | diphthongs | ||||||
| syllabic r | ඍ | 0D8D | ṛ | [ur] | ෘ | 0DD8 | ṛ | [ru, ur] | ඎ | 0D8E | ṝ | [ruː] | ෲ | 0DF2 | ṝ | [ruː, uːr] | syllabic r | ||||||
| syllabic l | ඏ | 0D8F | ḷ | [li] | ෟ | 0DDF | ḷ | [li] | ඐ | 0D90 | ḹ | [liː] | ෳ | 0DF3 | ḹ | [liː] | syllabic l | ||||||
| Display this table as an image | |||||||||||||||||||||||

Note that the transliteration of both ළ ්and ෟ is <ḷ>. This is not very problematic since the second one is extremely scarce.
Names of the graphemes
The letters of the English alphabet have more or less arbitrary names, e.g. em for the letter <m> or bee for the letter <b>. The Sinhala śuddha graphemes are named in a uniform way adding -yanna to the sound produced by the letter, including vocalic diacritics.[13][19] The name for the letter අ is thus ayanna, for the letter ආ āyanna, for the letter ක kayanna, for the letter කා kāyanna, for the letter කෙ keyanna and so forth. For letters with hal kirīma, an epenthetic a is added for easier pronunciation: the name for the letter ක් is akyanna. Another naming convention is to use al- before a letter with suppressed vowel, thus alkayanna.
Since the extra miśra letters are phonetically not distinguishable from the śuddha letters, proceeding in the same way would lead to confusion. Names of miśra letters are normally made up of the names of two śuddha letters pronounced as one word. The first one indicates the sound, the second one the shape. For example, the aspirated ඛ (kh) is called bayanu kayanna. kayanna indicates the sound, while bayanu indicates the shape: ඛ (kh) is similar in shape to බ (b) (bayunu = like bayanna).
Another method is to qualify the miśra aspirates by mahāprāna (ඛ: mahāprāna kayanna) and the miśra retroflexes by mūrdhaja (ළ: mūrdhaja layanna).
Ligatures
Certain combinations of graphemes trigger special ligatures. Special signs exist for an ර (r) following a consonant (inverted arch underneath), a ර (r) preceding a consonant (loop above) and a ය (y) following a consonant (half a ය on the right). [14] [20] [21] Furthermore, very frequent combinations are often written in one stroke, like ddh, kv or kś. If this is the case, the first consonant is not marked with a hal kirīma. [14] [17] [21]

The image on the left shows she glyph for śrī, which is composed of the letter ś with the vowel ī marked above and a ligature indicating the r below. The image on the right shows ligatures of ද(d)+ය(y) and ක(k)+ෂි (ṣi) on the Political science course advertisement.
Similarities to other scripts
Sinhala is one of the Brahmic scripts, and thus shares many similarities with other members of the family, such as the Tamil script and Devanāgarī. As a general example, /a/ is the inherent vowel in all three scripts.[1] Other similarities include the diacritic for <ai>, which resembles a doubled <e> in all three scripts (Sinhala e:ෙ, ai:ෛ; Tamil e:ெ, ai:ை, Devanāgarī pe:पे, pai:पै). The combination of the diacritics for <e> and <ā> yields <o> in all three scripts:
- Sinhala e: ෙ, Sinhala ā: ා, Sinhala o: ො
- Tamil e:ெ, Tamil ā: ா, Tamil o: ொ
- Devanāgarī e: ` ,Devanāgarī ā: ा, Devanāgarī o: ो
The diacritic for <au> is composed of preceding <e> and following <ḷ> in Sinhala (ෞ) and Tamil (ௌ).
Sinhala transliteration
Sinhala transliteration can be done in analogy to Devanāgarī transliteration. A problem is the transliteration of /අැ/, not found in Devanāgarī. This is <ä> in the German tradition of Wilhelm Geiger, and <æ> in the Anglophone tradition (e.g. James Gair).
Layman's transliterations in Sri Lanka normally follow neither of these. Vowels are transliterated according to English spelling equivalences, which can yield a variety of spellings for a number of phonemes. /ī/ for instance can be <ee>, <e>, <ea>, <i>, etc.
A transliteration pattern peculiar to Sinhala, and facilitated by the absence of phonemic aspirates, is the use of <th> for the voiceless dental stop, and the use of <t> for the voiceless retroflex stop. This is presumably because the retroflex stop /ʈ/ is perceived the same as the English alveolar stop /t/, and the Sinhala dental stop /t̪/ is equated with the English voiceless dental fricative /θ/.[22] Dental and retroflex voiced stops are alway rendered as <d>, though, presumably because <dh> is not found as a representation of /ð/ in English orthography.
Sinhala in Unicode
The Unicode range for Sinhala is U+0D80–U+0DFF. Grey areas indicate non-assigned code points.
| Sinhala Unicode.org chart (PDF) |
||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+0D8x | ං | ඃ | අ | ආ | ඇ | ඈ | ඉ | ඊ | උ | ඌ | ඍ | ඎ | ඏ | |||
| U+0D9x | ඐ | එ | ඒ | ඓ | ඔ | ඕ | ඖ | ක | ඛ | ග | ඝ | ඞ | ඟ | |||
| U+0DAx | ච | ඡ | ජ | ඣ | ඤ | ඥ | ඦ | ට | ඨ | ඩ | ඪ | ණ | ඬ | ත | ථ | ද |
| U+0DBx | ධ | න | ඳ | ප | ඵ | බ | භ | ම | ඹ | ය | ර | ල | ||||
| U+0DCx | ව | ශ | ෂ | ස | හ | ළ | ෆ | ් | ා | |||||||
| U+0DDx | ැ | ෑ | ි | ී | ු | ූ | ෙ | ෙ | ේ | ෛ | ො | ෝ | ෞ | ෟ | ||
| U+0DEx | ||||||||||||||||
| U+0DFx | ෲ | ෳ | ෴ | |||||||||||||
This character allocation has been adopted in Sri Lanka as the Standard SLS1134.
Computer support
Generally speaking, Sinhala support is less developed than support for Devanāgarī for instance. A recurring problem is the rendering of diacritics which precede the consonant and diacritic signs which come in different shapes, like the one for <u> for example.
Sinhala does not come built in with Windows XP, unlike Tamil and Hindi. However, all versions of Windows Vista come with Sinhala support by default, and do not require external fonts to be installed to read Sinhalese script.
For OS X, Sinhala font and keyboard support can be found at http://web.nickshanks.com/typography/ and at http://www.xenotypetech.com/osxSinhala.html
For Linux, the scim input method selector allows to use Sinhala script in applications like terminals or web browsers.
- History of Sinhala Software
Online resources
- Sinhala guide of the Sinhalese wikipedia (in English)
- Online Sinhala Unicode Writer
- Sinhala Unicode Support Group
- Online Unicode Converter
See also
- Dutch loanwords in Sinhala
- English loanwords in Sinhala
- Portuguese loanwords in Sinhala
- Tamil loanwords in Sinhala
Notes
- ↑ 1.0 1.1 1.2 1.3 Daniels (1996), p. 408.
- ↑ Gair and Paolillo 1997:15f.
- ↑ 3.0 3.1 3.2 3.3 Gair and Paolillo 1997.
- ↑ "Online edition of Sunday Observer - Business". Sundayobserver.lk. http://www.sundayobserver.lk/2004/09/19/fea29.html. Retrieved 2008-09-21.
- ↑ "Unicode Mail List Archive: Re: Sinhala numerals". Unicode.org. http://unicode.org/mail-arch/unicode-ml/y2006-m12/0127.html. Retrieved 2008-09-21.
- ↑ Roland Russwurm. "Old Sinhala Numbers and Digits". Sinhala Online. http://www.sinhala-online.com/sinhala-digits-number-page.html. Retrieved 2008-09-23.
- ↑ Daniels (1996), p. 380.
- ↑ http://www.lankalibrary.com/geo/dera1.html SU Deraniyagala, PRE- AND PROTOHISTORIC SETTLEMENT IN SRI LANKA
- ↑ Geiger (1995) p.2
- ↑ Matzel (1983) p.15,17,18
- ↑ Jayawardena-Moser (2004) p. 11
- ↑ Fairbanks et al. (1968), p.126
- ↑ 13.0 13.1 Karunatillake (2004), p. xxxii
- ↑ 14.0 14.1 14.2 Karunatillake (2004), p. xxxi
- ↑ Daniels (1996), p. 410.
- ↑ This letter is not used anywhere, neither in modern nor ancient Sinhala. Its usefulness is unclear, but it forms part of the standard alphabet (see http://unicode.org/reports/tr2.html)
- ↑ 17.0 17.1 Matzel (1983), p.8
- ↑ Matzel (1983), p.14
- ↑ Fairbanks et al. (1968), p. 366
- ↑ Fairbanks et al. (1968), p.109
- ↑ 21.0 21.1 Jayawardena-Moser (2004), p. 12
- ↑ Matzel(1983), p.16
References
- Daniels, Peter T. (1996). "Sinhala alphabet". The World's Writing Systems. Oxford, UK: Oxford University Press. ISBN 0-19-507993-0.
- Fairbanks, G.W.; J.W. Gair, MWSD Silva (1968). Colloquial Sinhalese (Sinhala). Ithaca, NY: South Asia Programm, Cornell University.
- Gair, J.W.; John C. Paolillo (1997). Sinhala. München, Newcastle: South Asia Programm, Cornell University.
- Geiger, Wilhelm (1995). A Grammar of the Sinhalese Language. New Delhi: AES Reprint.
- Jayawardena-Moser, Premalatha (2004). Grundwortschatz Singhalesisch - Deutsch (3 ed.). Wiesbaden: Harassowitz.
- Karunatillake, W.S. (1992). An Introduction to Spoken Sinhala ([several new editions] ed.). Colombo.
- Matzel, Klaus (1983). Einführung in die singhalesische Sprache. Wiesbaden: Harrassowitz.
External links
- Sinhala Unicode Character Code Chart
- Complete table of consonant-diacritic-combinations
- Complete table of consonant-diacritic-combinations as text
- Sinhala page at Omniglot
- Transliteration Add-on for Firefox (Tamil script to Sinhala script
- Sinhala Accepted As One Of The World’s Most Creative Alphabets
Image list for readers with font problems

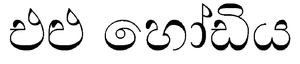
|
|||||||||||